隨著全球氣候變化加劇和水利信息化建設的深入推進,水雨情數據的采集頻率、覆蓋范圍和精細度呈指數級增長。如何高效處理這些海量、多源、異構的數據,實現實時計算分析、長期可靠存儲與精準歷史追溯,已成為現代水利行業數字化轉型的核心挑戰。本文將系統闡述水利業水雨情數據在數據處理與存儲服務方面的關鍵技術架構與實踐路徑。
一、 海量數據存儲:構建分層分級的彈性存儲體系
水利水雨情數據來源廣泛,包括自動氣象站、水文站、雷達、衛星遙感、視頻監控等,具有數據體量大(TB/PB級)、產生速度快、格式多樣(結構化、半結構化、非結構化)的特點。
- 混合存儲架構:
- 熱數據層:針對需要頻繁訪問和實時計算的近期高精度數據(如分鐘級雨量、實時水位),采用高性能的分布式存儲或全閃存陣列,保障低延遲讀寫。
- 溫數據層:對于訪問頻率較低但需快速響應的歷史數據(如過去數月的水情報表),可采用成本效益較高的分布式對象存儲或云存儲服務。
- 冷數據/歸檔層:對于用于長期追溯和法規遵從的多年甚至數十年的歷史原始數據,采用磁帶庫、藍光存儲或低成本的云歸檔服務,在確保數據安全的前提下極大降低存儲成本。
- 數據湖與數據倉庫結合:構建以數據湖為核心的基礎平臺,原生存儲所有原始數據,保留最大價值;根據業務主題(如洪水預報、水資源調度)建立數據倉庫或數據湖倉,對清洗、治理后的數據進行高效建模與分析。
二、 實時計算與分析:打造流批一體的數據處理引擎
水雨情監測預警、防汛抗旱指揮等業務對數據的實時性要求極高,需在秒級或分鐘級內完成數據匯聚、計算與決策支持。
- 流式計算框架:采用Apache Flink、Apache Storm或云廠商提供的流計算服務,對傳感器、遙測終端上報的數據流進行實時處理。可實現:
- 實時聚合:如區域面雨量實時計算。
- 閾值告警:實時判斷水位、雨量是否超警,并觸發預警信息推送。
- 關聯分析:實時關聯雨情、水情、工情數據,進行綜合研判。
- 批流一體化處理:統一的計算框架(如Flink)可同時處理實時流數據和歷史批量數據,實現算法模型在實時預警與歷史復盤中的一致應用,簡化技術棧。
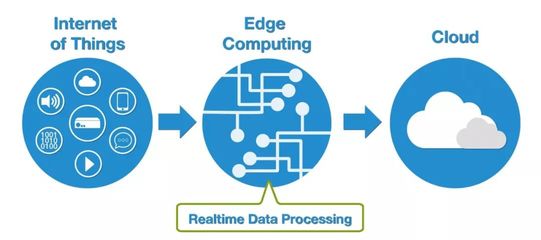
- 邊緣計算賦能:在網絡條件有限或對延遲極度敏感的關鍵站點(如水庫、重要防洪斷面),部署邊緣計算節點,實現數據本地預處理、異常過濾和輕量級實時分析,減少中心平臺壓力并提升響應速度。
三、 長期追溯與數據治理:確保數據的可查、可信、可用
水雨情數據是水利科學研究、工程規劃、災害評估的寶貴資產,其長期保存的完整性、一致性與可追溯性至關重要。
- 全生命周期元數據管理:為每條數據建立貫穿采集、傳輸、處理、存儲、使用、歸檔、銷毀全過程的元數據檔案,記錄其來源、質量、版本、訪問記錄等,實現數據血緣追溯。
- 數據標準化與質量管控:制定統一的數據標準與編碼體系,通過ETL/ELT流程進行自動化的數據清洗、校驗、修補和質量評分,確保入庫數據的一致性與可靠性。建立數據質量監控看板,對缺失、異常數據進行告警與跟蹤處理。
- 不可篡改與安全歸檔:對關鍵原始數據和應用哈希算法、數字簽名等技術,或利用區塊鏈存證,確保其長期不可篡改。建立規范的歸檔策略與檢索系統,使數十年的歷史數據也能被快速、準確地定位和調用。
四、 數據處理與存儲服務化:云原生與智能化演進
為應對業務靈活性和成本優化需求,數據處理與存儲正朝著服務化、云原生方向發展。
- 云平臺與混合云部署:利用公有云、私有云或混合云架構,按需獲取彈性的計算與存儲資源,避免一次性大規模硬件投入。云服務商提供的數據湖、數據倉庫、流計算、AI平臺等托管服務,能顯著降低運維復雜度。
- 一體化數據服務平臺:構建統一的數據中臺或數據服務平臺,將分散的數據存儲、計算、治理、分析能力以API或服務的形式提供給前端業務應用(如智慧水利大腦、移動APP),實現數據資產的集約化管理和價值高效釋放。
- AI驅動的智能管理:引入機器學習算法,用于數據異常自動檢測、存儲策略智能優化(自動冷熱分層)、計算資源動態調度等,提升系統自動化與智能化水平。
###
水利業水雨情數據的“存、算、溯”是一個系統性工程。通過構建分層彈性存儲體系、流批一體計算引擎、完善的數據治理框架,并擁抱云原生與服務化技術,能夠有效應對數據規模與業務復雜度的雙重挑戰。最終目標是形成覆蓋數據全生命周期的智能化管理能力,讓海量水雨情數據不僅存得下、算得快、查得到,更能用得好,為水旱災害防御、水資源優化配置、水生態保護修復提供堅實可靠的數據基石,賦能水利高質量發展與現代化進程。